Semi-automatic annotation of functional, semantic and pragmatic roles for Ob-Ugric texts
Based on particular, recurrent regularities in the syntax/morphosyntax of Ob-Ugric languages certain structures can be grouped by formal rules and based on this, sentences can be analysed by parsing. Syntactic and semantic functions can be assigned and basic patterns of information structure can be annotated. Reference tracking, i.e., the tracing of referents in the discourse, is part of the annotation as well. The parsing is based on the details concerning parts-of-speech (and – partially – information concerning additional levels of analysis, e.g., the indication of the objective conjugation, see below). Information on parts-of-speech was part of the glossing and processing in FLEx (Field Language Explorer). These parsings are exported, then edited with scripts and depicted in their own menu category (Edit Annotation) using four fields below the glossing. The automatic results can be checked, edited and completed here (semi-automatic annotation).
Short Description of the annotation’s outline and procedure
Step 1: Assigning Phrases / Parsing
Using the information on parts-of-speech from FLEx preset combinations are parsed as phrases, e.g., the sequence demonstrative pronoun before noun is parsed as nominal phrase (NP), the sequence adjective before noun as NP or the sequence prefix before verb as finite verbal phrase (finVP). The parser recognises one unit after another and groups them as phrases when a certain combination of units corresponds with a preset combination in the script. This way, fine-grained distinctions are possible (e.g., NP and postpositional phrase (PostP)). If one line in the glossing consists of several sentences (i.e., several predicates), they can be separated by square brackets. The components of each sentence are then represented in different colours.
For a better orientation and assignment of phrases the consecutive numbering of individual items is displayed together with the glossing. Phrases are marked by square brackets, corresponding boxes appear below the component that constitutes the right branch of the phrase, i.e., it appears in head-final position.
 Figure 1: Representation of several sentences (coloured) in the parsing; NM (ID 745, Nr. 2)
Figure 1: Representation of several sentences (coloured) in the parsing; NM (ID 745, Nr. 2)
The parsetree is depicted in the box phrasal annotation (see below). One can add or edit the result here, if necessary. (The original parsing result is displayed in a second box, changes are highlighted in colour by using a diff-function).
When using the so-called 'Reset Annotation' Mode (chosen by clicking on a box at the top of the page), the automatic tagging is re-done based on changes in the parsetree. In the default mode ('Regular Annotation' Mode), all original results remain as they were.
 Figure 2: Editable box Phrasal Annotation (above) and inactive box original parsing result (below) in comparison; NM (ID 745, Nr. 2)
Step 2: Annotation of syntactic, semantic and pragmatic roles
Figure 2: Editable box Phrasal Annotation (above) and inactive box original parsing result (below) in comparison; NM (ID 745, Nr. 2)
Step 2: Annotation of syntactic, semantic and pragmatic roles
After saving the parsing results the information of the box phrasal annotation are displayed in four lines below the glossed text.
These four lines contain the syntactic, semantic and pragmatic tags as well as the numeric assignment of the individual referents of a text.
 Figure 3: Functional, semantic and pragmatic annotation and numbering of referents; NM (ID 745, Nr. 2)
Figure 3: Functional, semantic and pragmatic annotation and numbering of referents; NM (ID 745, Nr. 2)
Many tags can be assigned automatically, but they need to be checked and – if necessary – corrected. For this purpose a list of standard tags is shown when the box is used. Referents need to be numbered manually. However, after saving (save functional annotations), the referents are saved as standard tags and are available in the drop down list.
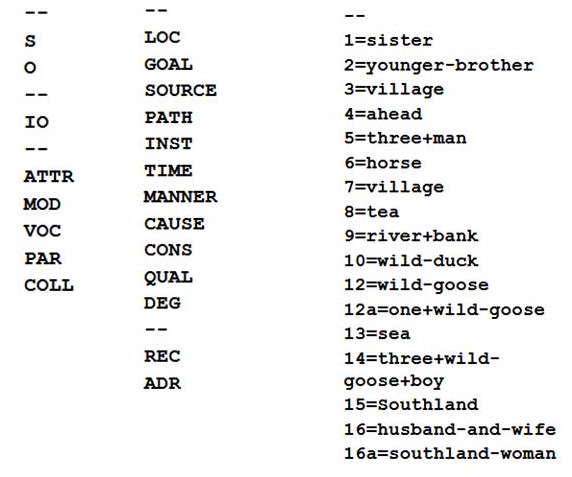 Figure 4: Drop-down lists functional tags (left), semantic tags (centre) and referents (right)
Figure 4: Drop-down lists functional tags (left), semantic tags (centre) and referents (right)
A third mode is offered, the Speech Annotation Mode, which can also be selected on top of the page: operating in a similar manner, an additional box above each sentence shows if it is in direct speech. Information is also parsed automatically and can be manually altered if necessary.
You’ll find a detailed instruction for annotation
here.
Theoretical Background
The parsing tool has been developed especially for the Ob-Ugric languages. It is based on information structural principles of the sentence in Ob-Ugric. This is i.a. decisive for word order, the assignment of a referent’s syntactic role as well as its representation in the sentence. The role of primary topic (or discourse-topic) corresponds to the subject of the sentence and realized with zero anaphora, e.g. That is why zero anaphoras are found in nearly every sentence. Since the zero gives no information which can be used to parse it, it is difficult to be annotated automatically, however. Here, we also make use of particular regularities which allow a majority of zero anaphors (i.e., subjects and also direct objects) to be added automatically in the parsing process. This way, in sentences that consist only of a VP a zero anaphor is added automatically before the VP, and in sentences with only a VP in objective conjugation two zero anaphors are inserted automatically.
 Figure 5: Visualisation of zero anaphora in the annotation; NM (ID 1229, Nr. 6)
Figure 5: Visualisation of zero anaphora in the annotation; NM (ID 1229, Nr. 6)
When word order is taken into account, the first zero is automatically assigned the role of the subject, the second that of the direct object.
 Figure 6: Zeros and their functional tags; NM (ID 1229, Nr. 6)
Figure 6: Zeros and their functional tags; NM (ID 1229, Nr. 6)
You can find a detailed description of the theoretical principles
here.
Technical realization
The annotation of syntactic units was technically realized by adding an input box below the already glossed corpus data, thereby allowing both to check and - if necessary - to correct the result of the automatic parsing as well as to check and, respectively, to complete the tagging results.
Phrasal units are recognized by a parsing algorithm, which is implemented in the PHP platform, sentence by sentence based on the part-of-speech tags in the corpus. The algorithm uses a simple and detailed phrase structre grammar, which was developed in the course of the project, and works with non-recursive rules (some grammatical features are also considered). Then it is completed with heuristics for the recognition of clauses. Also, analytic zero and px-elements are added in the end. This parsing result is transferred into the data base and the annotator can access it in the annotation menu; after confirming or, respectively, correcting the result, it is saved in an additional table in the database. The previously identified clausal and phrasal units are transformed into a PHP array and transferred to the tagging heuristics (see above). The result of the automatic tagging of these syntactic units are written into a corresponding table in the database (units are linked to the corpus via text and token number, analytic units are also included here), and immediately (via AJAX, i.e., asynchronous) displayed on the homepage. Here, the results of the tagging can - if necessary - be also corrected here. Furthermore, the referent tagging is conducted here. This is done manually, but supported by an additionally displayed selection of previously mentioned referents (also asynchronous, i.e., a new referent is immediately available in the next sentences).
The most common tags in annotation
Most tags were designed according to the usual abbreviations of functional, semantic and pragmatic roles and self-descriptive. The most common phrasal tags are e.g.:
| Tag |
Name |
| NP |
noun phrase |
| PronP |
pronoun phrase |
| zero |
zero anaphora |
| locNP |
noun phrase in locative case |
| postP |
postpositional phrase |
| VP |
verbal phrase |
There are some special tags which carry information used for annotating the other layers of tags. That is why there are several tags for verbal phrases, whether it is e.g. objective conjugation (okVP, in order to assign two zeros) or passive voice (passVP, in order to assign the semantic role “patient” to the subject). In all, the functional tags are also quite self-descriptive and are based on Dik 1997 e.g.:
| Tag |
Name |
| S |
subject |
| O |
direct object |
| IO |
indirect object |
| PRED |
predicate |
The inventory of semantic tags has been kept at a small size in order to guarantee both, correct automatic annotation and consistency for different editors. Therefor we do not distinguish patient and theme, e.g. Efforts in preparation of principles would not meet the results of automatic annotation. Instead, we have concentrated on specific features of Ob-Ugric typology. That is, e.g. the range of local adverbs or animacy.
| Tag |
Name |
| AG |
agent |
PAT |
patient |
| REC |
recipient |
| COM |
comitative |
| LOC |
locative |
| GOAL |
goal |
| SOURCE |
source |
| PATH |
path |
| INST |
instrumental |
Annotating pragmatic roles was the most challenging task and can only be performed up to a certain point. It was kept as simple as possible to perform a basic but correct pragmatic annotation. The automatic annotation again is based on distinctive features of the sentence based on information structure in Ob-Ugric. Since topicality of a referent results in low encoding material for reference (resulting in zeros for the most salient referents), all zeros are automatically tagged as TOP (topic) in reverse. The sentence predicate is by default tagged FOC (focus).
There are more tags available, if one wishes to refine this basic annotation manually.
| Tag |
Name |
Description |
| TOP |
topic |
The part of the sentence, which encodes the (role of) topic. |
| FRAME |
Frame-Settting |
Usually a introductory sentence a narration starts with or at the beginning of a new chapter including a new plot; usually prvoiding information about time, place and the person(s) involved. |
| FOC |
focus |
The part of the sentence, which expresses the focus part (in this case synonymous to new information). |
Referents, that take part in the plot, are continually numbered according to their first appearance. Once a referent got its number, it will - together with the lexical phrase it was introduced with - occur in the drop-down list. If several referents perform an action together, this can also be mark with corresponding tags.
| Tag |
Description |
| 1 |
referent 1 |
| 1+2 |
referent 1 and 2; dual |
| 1+2+3 |
referent 1, 2 and 3; plural |
| 2a |
Tag referent 2 refers to a group. Referent 2a is one member of this group that now performs an action alone. |
We perform an uni-dimensional annotation, equivalent to the glossing. This also effects the annotation of subordinated clauses. Their handling as well as the annotation of other characteristics (possessive constructions, e.g.) are described
here in more detail. You’ll also find the full list of tags there.
Results and further Use
The annotation can help depict the interaction between grammatical and pragmatic information and their effect on the sentence structure and, e.g., specific mechanisms like the dative shift can be detected. Furthermore, the number, the frequency of occurrence and the choice of the referential device for the referents in the text can be displayed and the topicality of individual referents can be stated.
The annotated text can be printed as pdf and, e.g., can be used as source in appendices in text analyses. Alternatively individual lines can be exported as examples directly into LaTeX.
Link to the annotated text corpus.
