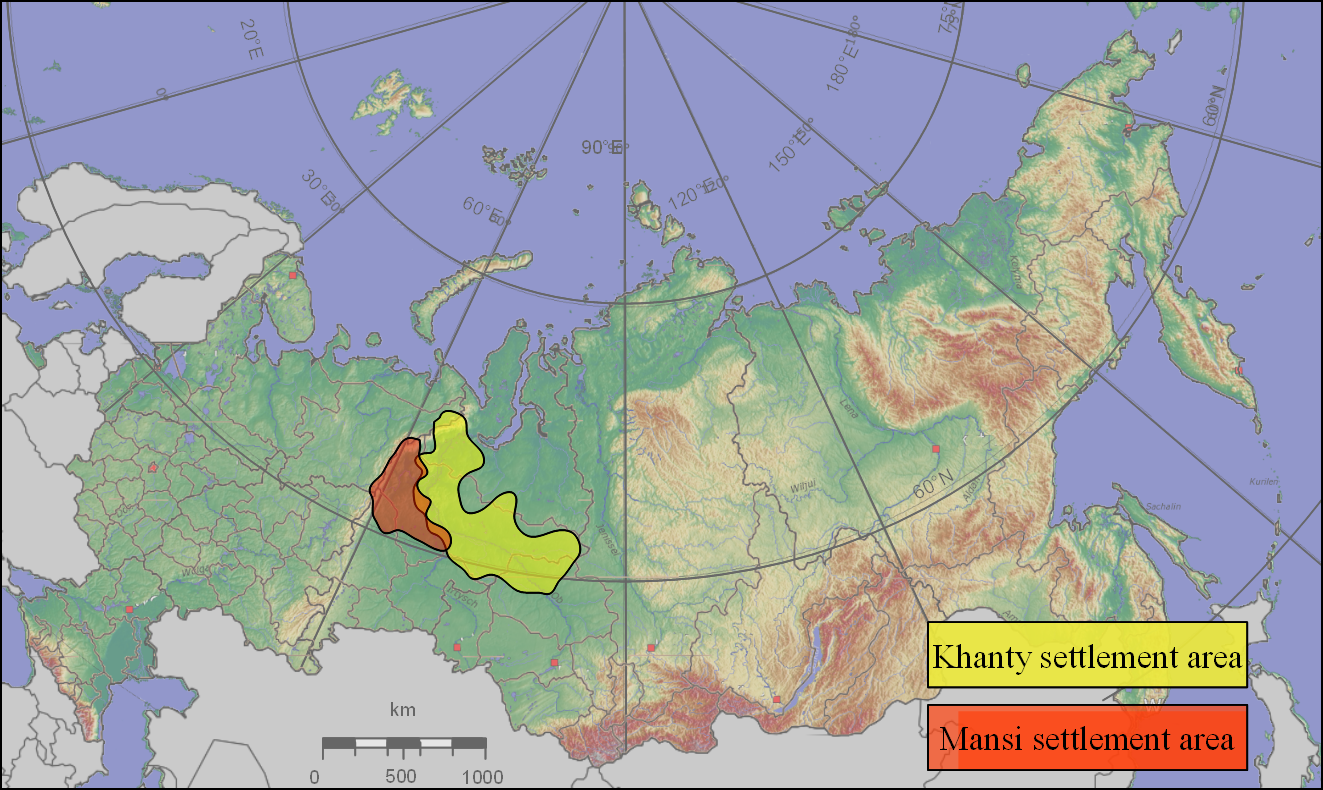
Über OULIm August 2009 wurde das Projekt OUL „Ob-Ugrische Sprachen: konzeptionelle Strukturen, Lexikon, Konstruktionen, Kategorien“ als gemeinsames Forschungsprojekt ins Leben gerufen. In Zusammenarbeit sollen Beschreibungen und moderne linguistische Analysen der beiden verwandten und gefährdeten ob-ugrischen Sprachen Chantisch (Ostjakisch) und Mansisch (Wogulisch) online verfügbar gemacht werden. Im Chantischen werden speziell die Dialekte von Surgut und Kazym, im Mansischen der Nord- und der Ostdialekt behandelt. Das Projekt ist als Teil des EUROCORES Programm ausgewählt, das unter der Leitung der European Science Foundation steht und von verschiedenen europäischen Organisationen – wie DFG (Deutsche Forschungsgemeinschaft), FWF (Österreichischer Wissenschaftsfond), OTKA (Ungarischer Wissenschaftlicher Forschungsfond) und der Akademie von Finnland (Finnischer Forschungsfond) – finanziert wird. Ziel von EUROCORES war es, die empirische Untersuchung von nicht ausreichend dokumentierten gefährdeten Sprachen zu fördern. Innerhalb von drei Jahren haben Linguisten aus Deutschland (LMU München), Österreich (Universität Wien), Finnland (Universität Helsinki) und Ungarn (Eötvös Loránd Universität Budapest sowie Universität Szeged) ein beispielloses virtuelles Forschungsumfeld geschaffen. Dabei haben sich alle Forschungsteams regelmäßig getroffen – es fanden insgesamt vier große Workshops des Ob-BABEL-Projekts statt: 2009 in Wien, 2010 in Budapest, 2011 in München und 2012 in Helsinki. Die Forschungsteams wurden außerdem von zahlreichen kooperierenden Forschern (Linguisten und Ethnologen) sowie von muttersprachlichen Sprechern ob-ugrischer Dialekte unterstützt. Die Highlights der linguistischen Analyse sind:•Die Entwicklung einer an die Besonderheiten der ob-ugrischen Dialekte angepassten Transliteration, zusammengefasst in phonemischen Transliterationstabellen; •Die Entwicklung von Glossierungen und Abkürzungen für Kategorien, die in den Leipzig Glossing Rules nicht aufgeführt werden (z.B. für Suffixe, die Objekt-Agreement ausdrücken); •Die Hierarchie von verbalen Kategorien mit der Opposition „Realis – Irrealis“; die Kategorie „Realis“ beinhaltet den Indikativ und Mirativ, beide mit Tempusformen, die Kategorie „Irrealis“ (Optativ und Imperativ) kennt keine Tempora; •Eine Re-Analyse und Verfeinerung grammatischer Kategorien: z.B. Mirativ, der früher als Evidentialis oder gar nicht beschrieben wurde; bei den Personalpronomen behandeln wir zwei Stämme im Paradigma, den „status directus“ und den „status obliquus“; letzterer wird mit Kasusaffixen verwendet, inklusive Null in der Position des direkten Objekts (und wurde früher als „Akkusativ“ beschrieben); verschiedene „Subparadigmata“ der Possessivsuffixe in unterschiedlichen Funktionen usw.; •Eine Analyse der Informationsstruktur im Ob-Ugrischen: Dabei handelt es sich um komplexe Strategien, bei denen mehrere verschiedene sprachliche Mittel verwendet werden, wie etwa das Passiv, Objekt-Agreement oder Nullanapher als Topikalisierungsmarker, usw. Die wichtigsten Errungenschaften des Projekts waren:•Die Webseite des Projekts als virtuelles Forschungsumfeld, das einen Zugang zu miteinander verbundenen Modulen bietet: Die Interfaces für die Erstellung von Korpora/Wörterbüchern und Präsentationen, ein Tool zur Verwaltung und Darstellung einer umfassenden Bibliographie, um nur ein paar zu nennen. •Die Bibliographie kann nach verschiedenen Parametern durchsucht werden (etwa 7000 Einträge mit vollständiger bibliographischer Beschreibung). Sie enthält eine große Auswahl an Publikationen über die ob-ugrischen Sprachen und ihre Dialekte, sowie zur Ethnologie, Soziolinguistik und zu Kultur, Leben und Mythologie der ob-ugrischen Völker. Die Eingabe ist sowohl in kyrillischer als auch in lateinischer Schrift möglich und wird durch eine Textvorerkennung vereinfacht; zudem gibt es eine phonetische Suchfunktion, wobei das System verschiedene Schreibvarianten erkennt und verknüpft. Die Zusammenstellung der Bibliographie war zunächst nicht im Forschungsantrag vorgesehen, wurde jedoch im ersten Jahr des Projektes notwendig. •In der e-Bibliothek wird eine umfangreiche Sammlung an Materialien zu den ob-ugrischen Sprachen und Kulturen zur Verfügung gestellt. Sie enthält auch einzigartiges Unterrichtsmaterial, das von den Projektmitarbeitern zur Verfüdung gestellt wurde (u.a. drei vor kurzem erschienene Monographien zur chantischen Ethnographie von Prof. Dr. Lukina; praxisnahe Kursbücher für das Kazym-Chantische von Prof. Dr. Solovar und Dr. Koškarjeva). Auch eine Auswahl an Multimediaressourcen, wie etwa eine Datenbank für chantische Lieder, Feldforschungsfotos und Videoclips ist hier zu finden. •Das Textkorpus, mit Texten aus dem Nordmansischen (130 in IPA transliterierte Texte, davon 18 glossiert), Kazym-Chantischen (46/24) und Surgut-Chantischen (41/20). Alle Texte wurden mithilfe der frei zugänglichen Software Fieldworks Language Explorer (FLEx) von SIL analysiert (ohne syntaktisch-pragmatisches Tagging). •In der e-Grammatik ist es möglich, die Materialien 1) nach Dialekt 2) nach linguistischem Fachgebiet oder 3) nach Präsentationsform (einfache Textkommentare, Tabellen, ein interaktiver auf vollständigen Flexionstabellen basierender Formengenerator für einige Lexeme) zu filtern. Ein Großteil der e-Grammatik besteht aus einer grundlegenden linguistischen Beschreibung, da eine bessere Beschreibung des Ob-Ugrischen schon ab dieser Stufe beginnt. Die publizierten Materialien stellen gleichzeitig die für die Analyse entwickelten Tools dar, z.B. die Templates für die grammatische Position. Für jeden Dialekt wurde ein Morphemglossar erstellt, das sowohl mit der e-Grammatik als auch mit dem Textkorpus verlinkt wurde. •Im e-Wörterbuch sind Suchanfragen in einem oder bis zu vier Dialekten möglich. Viele Einträge werden durch ethnographische Materialien (Bilder, Videos, Kommentare) und etymologische Informationen auf Basis von Uralonet (das digitalisierte Uralisches Etymologisches Wörterbuch, UEW) ergänzt; soweit möglich, wurde im Lexikoneintrag der entsprechende Eintrag in Uralonet verlinkt. Die interaktive Konkordanzfunktion zwischen den glossierten Texten und dem Lexikon wurde programmiert. Die Einträge basieren auf dem Textkorpus und wurden mit Informationen aus bereits bestehenden gedruckten Lexika ergänzt; dazugehörige (z.B. dialektale) Varianten und Allomorphe werden angegeben. Alle Lexeme wurden auf Englisch und Russisch, teilweise auch auf Deutsch, übersetzt und mit bis zu 56 linguistischen Parametern näher charakterisiert. Bis Projektende existieren 6860 Einträge (Ostmansisch: 1147 Einträge, Nordmansisch: 2473, Kazym-Chantisch: 2168, Surgut-Chantisch: 1072). Besonders ist die online verfügbare Version des Mansisch-Ungarisch-Deutschen Wörterbuchs von Munkácsi / Kálmán (1986) hervorzuheben, welches das Ergebnis der unermüdlichen Arbeit des ungarischen Teams ist. Es ermöglicht den Benutzern den Zugriff auf ausführliche semantische, dialektologische, etymologische Informationen in diesem komplexen Wörterbuch und seinen unbezahlbaren erläuternden Materialien. Da die Daten im Wörterbuch von Munkácsi / Kálmán etymologisch angeordnet sind, ist es nur schwer ohne linguistisches Wissen verwendbar. Die Onlineversion ist durch seine phonetische Suchfunktion leichter benutzbar.
Fónyad, Bauer (2012). "A Plea for a Grammar Analysis of Northern Mansi Free of Valuation: Inflection Tables, Position Slot Morphology, and Tree Hierarchies". In: Finnisch-Ugrische Mitteilungen 36 p. 41-74 Virtanen (2014). "Pragmatic direct object Marking in Eastern Mansi" In: Linguistics 52:2 p. 391–413 Skribnik, Janda: "Northern Mansi Miratives" EUROBABEL Final Conference (Leiden, NL) (August 24 2012) Skribnik, Kováts, Bauer: "The Relevance of Language Documentation for Language Users" EuroBABEL Themed Panel at Conference on Language Endangerment: Documentation, Pedagogy, and Revitalization (Cambridge GB) (March 25, 2011) Bauer: "Aus der Korpus-Werkstatt des Projektes "Ob-Ugric Languages": Vernetzung und Modularität in Arbeitsablauf, Korpusstrukturierung und Präsentation – Potential und Hindernisse" Workshop II of doctoral programs of the universities of Munich and Zurich (November 12, 2010) Themed round table (Laakso - Riese - Bakró-Nagy - Forsberg - Skribnik): "Research projects in Finno-Ugric studies" Congressus Internationalis Fenno-Ugristarum (Piliscsaba, HUN) (August 9-14, 2010) Kováts: "Online-Korpus der Surgut-chantischen Sprache (Projekt EuroBABEL)" Workshop I of doctoral programs of the universities of Munich and Zurich (May 7, 2010) Skribnik: „EuroBABEL project Ob-Ugric languages and cooperation of institutes for Finno-Ugric studies” 14. Deutscher Finnougristentag (Cologne, GER) (November 08, 2009) Virtanen: "Remarks on Object Marking in Eastern Mansi". New trends in Uralistics: typology, syntax, sociolinguistics (Szeged, HUN) (September 3-5, 2009) Für die Gesamtliste der Publikationen besuchen Sie die Sektion Events & Publications; des Weiteren finden Sie Beiträge unserer Mitarbeiter und kooperierenden Partner in unserer e-Bibliothek. Offizielles Poster & Broschüre
|
|